被翻译的论文在 : http://ieeexplore.ieee.org/document/8048116/
《Shadowsock翻墙流量检测算法》论文翻译
翻译前言
随着机器学习技术的火热,国内不少实验室一窝蜂的将机器学习纳入自己的科研课题研究之中,这样可以更好的找到发论文的结合点。我之前的所在实验室就曾将机器学习引入漏洞挖据的研究之中,取到了很好的效果。但是据我所知,有些研究课题将机器学习引入并没有带来多少收益。本文将机器学习引入Shadowsock翻墙流量的检测,旨在提高准确率节省人力,我认为准确率的提高主要在于:特征的抽象和训练数据的规模。论文中并没有详细的数据说明,我对于准确率部分的说明有保留意见。
原文标题
The Random Forest based Detection of Shadowsock's Traffic
http://ieeexplore.ieee.org/document/8048116/
http://ieeexplore.ieee.org/document/8048116/
作者
Ziye Deng1, Zihan Liu1, Zhouguo Chen2, Yubin Guo2
网络安全中心
通信安全实验室
摘要
随着匿名通信技术的发展,网络监控越来越困难。 如果可以有效地识别匿名流量,则可以防止这种技术的滥用。 由于机器学习的研究正在迅速发展,本文将随机森林算法(一种半监督学习方法)应用于Shadowsocks的流量检测。 通过收集训练组,采集特征,训练模型和预测结果来应用随机森林算法,在实验中,我们可以获得超过85%的检测精度。 随着熟练数据设置和测试设置的规模增加,检测精度率逐渐增加,直到取向恒定。 下一步,我们将对训练数据,测试设置和功能集进行几个调整,以减少检测时的误报率。
关键词
随机森林算法; 机器学习
一.引言
随着近年来海外新闻的需求量不断增加,包含政治,经济,民主,金融,科技等方面的敏感信息。为了摆脱国家的防火墙获取更多的消息,越来越多的人已经学会了如何使用代理软件获取相关的敏感资料。然而,高速开发的代理软件通过翻越防火墙,已经成为广播大量敏感信息的非法工具。因此,隐蔽交易的发生频率很高。为了有效地防止这些事情发生,并立即发现和逮捕这些罪犯,我们不仅要对来自代理软件的流量进行检测和分类,而且要分别给具有某些特征的加密流量标记不同的可疑标签。这些工作可以为监督人员提供详细的信息和数据,进行解密工作和内容分析。
在本文中,我们简要介绍了Shadowsocks的运行原理[1]。下一步是从该代理软件中全面分析流量,并从该软件获取功能信息。指出特征数据和信息,我们使用Libpcap [2]来解决协议,使用机器学习来训练特征数据的某些部分,并在构建模型之后识别。
在本文中,我们简要介绍了Shadowsocks的运行原理[1]。下一步是从该代理软件中全面分析流量,并从该软件获取功能信息。指出特征数据和信息,我们使用Libpcap [2]来解决协议,使用机器学习来训练特征数据的某些部分,并在构建模型之后识别。
本文的结构如下:第二部分介绍本文的准备工作和贡献。 我们将在第3节简单介绍该软件的运行原理。第4节将全面展示来自该代理软件的每个流量的检测原理。 相关的实验室结果将在第5节中声明。最后,第6节将是本文的总结。
二.相关工作
为了更好地了解Shadowsocks的流量特征,我们参考了许多论文和材料来了解其运行机制,以确定检测Shadowsocks流量的方法并提取所需的特征信息。众所周知,Shadowsocks的运行非常稳定-几乎是我国最稳定和流畅的代理软件,包括在翻墙的效率和速度(了不起!!!)。然而,目前的工作研究在检测Shadowsocks的流量方面并没有显着的结果。由于Shadowsocks的稳定性和效率,我们可以使用Shadowsocks连接Anony-mous network TOR [3],VPN [4]等代理,这成为防火墙的严重威胁,给安全带来更严重的问题。在本文中,我们提出了一种基于随机森林算法的Shadowsocks检测方法[5]。我们通过使用机器学习处理Shadowsocks的流量[6],之后我们可以通过使用半监督学习[7]算法来检测Shadowsocks流量,精度超过85%,这可以保护和处理敏感数据来源的潜在危险。
目前,将机器学习算法应用于流量检测方面没有太多的研究。流量检测方法主要取决于人为识别,如阻塞端口,IP等。如果我们可以使用半监督或无监督的机器学习算法,则可以通过机器简单地完成流量检测工作,这可以减少人员的工作量提高检测效率。结合机器学习算法和流量检测也是本文的贡献之一。
目前,将机器学习算法应用于流量检测方面没有太多的研究。流量检测方法主要取决于人为识别,如阻塞端口,IP等。如果我们可以使用半监督或无监督的机器学习算法,则可以通过机器简单地完成流量检测工作,这可以减少人员的工作量提高检测效率。结合机器学习算法和流量检测也是本文的贡献之一。
三.背景
A.为什么很难检测到Shadowsocks?
Shadowsocks难以被发现的主要原因是Shadowsocks的运行机制很简单。像代理软件的大多数原则一样,Shadowsocks首先建立一个基于SSH [8]的加密通道,其中包含防火墙外的服务器;其次,Shadowsocks通过使用已建立的通道进行代理,这意味着通过SSH服务器请求真正的服务器。最后,通过SSH服务器使用已建立的通道发回响应数据。由于SSH本身是基于RSA [9]加密技术,因此防火墙在传输过程中无法分析加密数据的关键字,从而防止重连接问题。 SSH存在有针对性的干扰问题,所以Shadowsocks将socks5 [10]协议分为服务器端和客户端两部分。详细过程如下:首先,客户端发送请求,根据sock5与本地Shadowsocks进行通信。由于本地的Shadowsocks通常是本地主机或路由器和任何其他机器,它们不会经过防火墙,因此它们不会受到防火墙的干扰。在Shadowsocks客户端和服务器之间,他们可以通过各种加密方式进行通信,因此,通过防火墙的数据包将显示为公共TCP数据包。这些数据包没有明显的功能,防火墙无法解密这些数据,导致防火墙无法检测和干扰这些数据。最后,Shadowsocks服务器解密接收到的加密数据,并向实际服务器发送真实请求,并将响应数据发送给Shadowsocks客户端。详细过程如图1所示。我们可以看到,Shadowsocks的每个运行步骤都绕过了防火墙的检测,并且不会被防火墙干扰。这就是为什么很难人为地检测到Shadowsocks的原因。
图1 Shadowsocks的通信原理
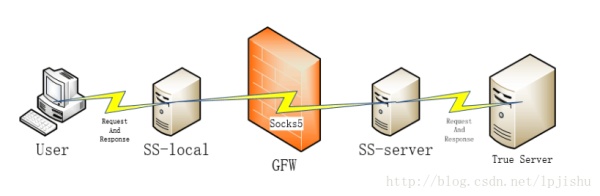
这里写图片描述
B.随机森林算法
统计学中,随机森林算法是一种分类器算法。 分类器是确定给定样本数据应属于哪一类的算法。 随机森林包含许多决策树,训练样本并进行预测。 预测结果由随机森林中大多数决策树决定。 在我们的方法中,我们将使用随机森林算法将流量分类为两个分类,一个是“Shadowsocks流量”,一个是“无Shadowsocks流量”。
C.定义
1)数据包:数据包是网络中用于传输和交换数据的单元。 数据包包含的传输数据长度不一致。 在传输过程中,数据包将被打包成帧。 其方法是以特定格式添加多个信息,如数据包头,数据包类型,消息长度,数据包版本等。
2)数据流:IP网络通常可以将网络流量定义为五元组:源IP地址,目的IP地址,源IP端口,目的IP端口和协议号。 因此,具有相同五元组的网络分组可以被看作是一个相同的流。
3)Biflow:二进制流,具有相同的源IP地址,目的IP地址,源IP端口,目的IP端口和协议号数据集。
4)hostProfile:一组在一个主机中经过一段时间后被过滤的数据包(文件保存为.pcap格式)。
2)数据流:IP网络通常可以将网络流量定义为五元组:源IP地址,目的IP地址,源IP端口,目的IP端口和协议号。 因此,具有相同五元组的网络分组可以被看作是一个相同的流。
3)Biflow:二进制流,具有相同的源IP地址,目的IP地址,源IP端口,目的IP端口和协议号数据集。
4)hostProfile:一组在一个主机中经过一段时间后被过滤的数据包(文件保存为.pcap格式)。
四.我们提出的方法
A.使用随机森林算法来检测Shadowsocks的流量。
随机森林由许多CART(分类和回归树)组成[11]。每组训练数据使用的决策树从总的训练数据集合中取出,取出的单组训练数据将被放回总训练集合。当训练每棵树的节点时,从训练组集合中取出用过的训练组,其中列出的训练组不会退回总训练集合中。假设训练数据总数为C,比例可以为C,sqrt(C),1 / 2sqrt(C),log2(C)。在我们的实验中,我们使用默认值sqrt(C)。
当使用随机森林算法时,有几个步骤可以检测到Shadowsocks的流量,如下所示:
1)确定训练过程所需的所有数据集和参数,包括训练数据组P,测试集T,特征维度F,CART t的数量,每个CART的深度d,节点使用的功能数f,终止包括节点s中最小样本的条件,节点m中的信息增益最小。
2)从总训练数据集合P去除训练数据,训练数据将返回,训练数据组数量等于训练组P(i)的数目,i表示数。将P(i)设置为根,并从根开始训练。
3)如果当前节点没有达到终止条件,则从F维特征向量随机抽取f个特征,这些f特征将不会返回到F维特征向量。从这些f特征中选择具有最佳分类效果的特征k及其阈值th。并利用这些k特征进行判断。如果值小于阈值,样本将被分类为左侧节点,如果该值大于阈值,则样本将被分类为右侧节点。如果当前节点达到终止条件,则将当前节点设置为叶节点。这个叶节点的预测输出是当前节点样本集中最大的分类c(j),假设当前样本集中的c(j)的速率是概率。
4)训练所有节点,直到所有节点被标记为叶节点或被训练。
5)训练所有CART,直到所有CART被训练。
6)预测训练数据组T,预测过程就像训练过程一样。 从当前CART根节点确定,如果小于当前节点的阈值,节点将进入左侧节点,如果大于当前节点的阈值,节点将进入右侧节点。 确定过程将维持直到叶节点输出预测结果。
7)对CART输出的所有预测值进行确定和计算,所有树中预测概率的最大和是预测结果,这意味着c(j)的每个概率的总和。
当使用随机森林算法时,有几个步骤可以检测到Shadowsocks的流量,如下所示:
1)确定训练过程所需的所有数据集和参数,包括训练数据组P,测试集T,特征维度F,CART t的数量,每个CART的深度d,节点使用的功能数f,终止包括节点s中最小样本的条件,节点m中的信息增益最小。
2)从总训练数据集合P去除训练数据,训练数据将返回,训练数据组数量等于训练组P(i)的数目,i表示数。将P(i)设置为根,并从根开始训练。
3)如果当前节点没有达到终止条件,则从F维特征向量随机抽取f个特征,这些f特征将不会返回到F维特征向量。从这些f特征中选择具有最佳分类效果的特征k及其阈值th。并利用这些k特征进行判断。如果值小于阈值,样本将被分类为左侧节点,如果该值大于阈值,则样本将被分类为右侧节点。如果当前节点达到终止条件,则将当前节点设置为叶节点。这个叶节点的预测输出是当前节点样本集中最大的分类c(j),假设当前样本集中的c(j)的速率是概率。
4)训练所有节点,直到所有节点被标记为叶节点或被训练。
5)训练所有CART,直到所有CART被训练。
6)预测训练数据组T,预测过程就像训练过程一样。 从当前CART根节点确定,如果小于当前节点的阈值,节点将进入左侧节点,如果大于当前节点的阈值,节点将进入右侧节点。 确定过程将维持直到叶节点输出预测结果。
7)对CART输出的所有预测值进行确定和计算,所有树中预测概率的最大和是预测结果,这意味着c(j)的每个概率的总和。
B. Shadowsocks'biflow的特点
从上述随机森林算法的过程可知,我们需要确定训练数据组和特征尺寸。 根据网络数据包hostProfile和biflow的属性,我们提出几个功能。 然后,我们捕获一大堆Shadowsocks的流量,提取某些特征值,并将其保存为训练组。 具体功能部分如表1所示。 除此之外,我们还有一个3000维的向量,它记住在整个通信过程中是否出现上游和下游数据包的大小。
表1 部分特征

这里写图片描述
五.实验和结果
A.随机森林算法的过程,计算和价值
实验步骤:
•捕获纯粹的Shadowsocks流量,处理这些流量,提取和保存某些功能。
•使用随机森林算法来模拟这些值。 在随机森林算法中,我们将CART的总值设置为100,将等级标准设置为“gini”,将提取要素的数量设置为sqrt(C),C是特征维度的总数。 树的最大深度设置为无,直到所有节点被识别为止。 分类结果标记为两个分类,“是”和“否”。 剩下的参数被设置为Python的默认参数RandomForestClassifer函数。
•捕获检测流量,包括Shadowsocks流量和没有Shadowsocks的流量。 提取某些特征值并保存。 最后,使用随机森林算法构建模型并进行预测
•捕获纯粹的Shadowsocks流量,处理这些流量,提取和保存某些功能。
•使用随机森林算法来模拟这些值。 在随机森林算法中,我们将CART的总值设置为100,将等级标准设置为“gini”,将提取要素的数量设置为sqrt(C),C是特征维度的总数。 树的最大深度设置为无,直到所有节点被识别为止。 分类结果标记为两个分类,“是”和“否”。 剩下的参数被设置为Python的默认参数RandomForestClassifer函数。
•捕获检测流量,包括Shadowsocks流量和没有Shadowsocks的流量。 提取某些特征值并保存。 最后,使用随机森林算法构建模型并进行预测
B.数据采集
在本地主机上捕获1G Shadowsocks的流量,在C中使用Libpcap lib来解决这些流量。我们用提取的特征进行计算,得到所有的特征值,并将它们作为训练数据组保存到数据库中。捕获1G无Shadowsocks在本地主机的流量10次,使用libpcap处理这些数据。之后,随机捕获超过1G的Shadowsocks流量,并且在没有任何Shadowsocks的流量的26个主机中,以相同的方式处理这些数据,并以测试集的形式存储到数据库中。
C.如何计算。
根据随机森林算法的判断结果,我们人为地验证了他们对随机森林算法的训练集合和准确率的有效性。接下来,我们测试由不同尺寸的训练组构建的模型的检测精度。
从图2可以看出,本实验中特征集的选择效果良好。也可以证明,随机森林算法在Shadowsocks的流量检测中的应用具有显着的效果。我们也可以从图2得出结论,使用较大的测试集可以得到更准确的结果。
从图2可以看出,本实验中特征集的选择效果良好。也可以证明,随机森林算法在Shadowsocks的流量检测中的应用具有显着的效果。我们也可以从图2得出结论,使用较大的测试集可以得到更准确的结果。
图2 检测精度

图3说明越大的训练集构造的模型具有越高的检测率)
图3 不同训练集合大小的精度检测

六.结论
在我们的实验中,我们验证了将机器学习应用于流量检测是非常有效的。 我们也得出结论,随着训练数据规模的增加,模型更加完善,检测准确率也将提高。 另外,随着测试集的规模增加,检测的准确率也将增加。 将这种半监督机器学习算法应用于流量检测可以与人工方式相比,发现可以降低误报率和成本。
在我们的方法中,我们采用了许多功能,可以在一定程度上提高检测精度。 然而,它也增加了系统负担,这使得模型相对冗余。 在未来的工作中,我们将深入研究功能,找出最有效的特征属性,排除多个不必要的特征,优化和简化模型,提高整个系统的效率。
致谢
作者要感谢Zhuo ZhongLiu博士和Li Ruixing高工对这项工作的深刻的意见和讨论。 感谢网络安全中心为实验提供环境。 感谢通信安全实验室提供深入研究的机会。
参考文献
[1] Xu, Weiai Wayne, and Miao Feng. "Networked creativity on the censored web 2.0: Chinese users’ Twitter-based activities on the issue of internet censorship." Journal of Contemporary Eastern Asia 14.1 (2015): 23-43.
[2] Jacobson, Van, and S. McCanne. "libpcap: Packet capture library." Lawrence Berkeley Laboratory, Berkeley, CA(2009).
[3] Fagoyinbo, Joseph Babatunde. The Armed Forces: Instrument of Peace, Strength, Development and Prosperity. AuthorHouse. 2013- 05-24 [29 August 2014]. ISBN 9781477226476.
[4] Seid, Howard A., and Albert Lespagnol. "Virtual private network." U.S. Patent No. 5,768,271. 16 Jun. 1998.
[5] Liaw, Andy, and Matthew Wiener. "Classification and regression by randomForest."R news 2.3 (2002): 18-22.
[6] Goldberg, David E., and John H. Holland. "Genetic algorithms and machine learning." Machine learning 3.2 (1988): 95-99.
[7] Zhu, Xiaojin. "Semi-supervised learning." Encyclopedia of Machine Learning. Springer US, 2011. 892-897.
[8] Ylonen, Tatu, and Chris Lonvick. "The secure shell (SSH) protocol architecture." (2006).
[9] Kaliski, Burt. "PKCS# 1: RSA encryption version 1.5." (1998).
[10] Krawetz, Neal. "Anti-honeypot technology." IEEE Security & Privacy 2.1 (2004): 76-79.
[11] Fonarow, Gregg C., et al. "Risk stratification for in-hospital mortality in acutely decompensated heart failure: classification and regression
tree analysis." Jama 293.5 (2005): 572-580.
[2] Jacobson, Van, and S. McCanne. "libpcap: Packet capture library." Lawrence Berkeley Laboratory, Berkeley, CA(2009).
[3] Fagoyinbo, Joseph Babatunde. The Armed Forces: Instrument of Peace, Strength, Development and Prosperity. AuthorHouse. 2013- 05-24 [29 August 2014]. ISBN 9781477226476.
[4] Seid, Howard A., and Albert Lespagnol. "Virtual private network." U.S. Patent No. 5,768,271. 16 Jun. 1998.
[5] Liaw, Andy, and Matthew Wiener. "Classification and regression by randomForest."R news 2.3 (2002): 18-22.
[6] Goldberg, David E., and John H. Holland. "Genetic algorithms and machine learning." Machine learning 3.2 (1988): 95-99.
[7] Zhu, Xiaojin. "Semi-supervised learning." Encyclopedia of Machine Learning. Springer US, 2011. 892-897.
[8] Ylonen, Tatu, and Chris Lonvick. "The secure shell (SSH) protocol architecture." (2006).
[9] Kaliski, Burt. "PKCS# 1: RSA encryption version 1.5." (1998).
[10] Krawetz, Neal. "Anti-honeypot technology." IEEE Security & Privacy 2.1 (2004): 76-79.
[11] Fonarow, Gregg C., et al. "Risk stratification for in-hospital mortality in acutely decompensated heart failure: classification and regression
tree analysis." Jama 293.5 (2005): 572-580.
翻译仓促,如有错误,欢迎指正~
附:转载授权截图:

附:转载授权截图:
没有评论:
发表评论